When an Oracle instance starts, multiple background processes start. A background process is a block of executable code designed to perform a specific task. Figure 1-6 shows the relationship between the background processes, the database, and the Oracle SGA. In contrast to a foreground process, such as a SQL*Plus session or a web browser, a background process works behind the scenes. Together, the SGA and the background processes compose an Oracle instance.
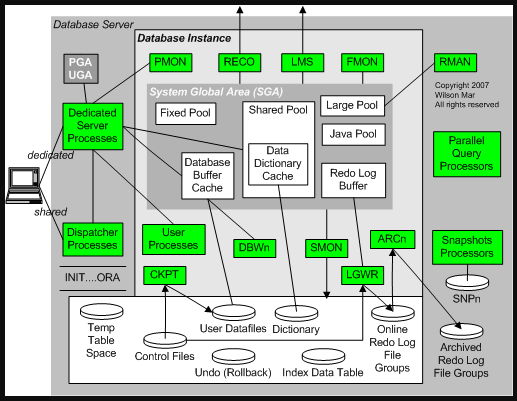
FIGURE 1-01. Oracle background processes
Background Processes in Oracle
To maximize performance and accommodate many users, a multiprocessed Oracle database system uses background processes. Background processes are the processes running behind the scenes and are meant to perform certain maintenance activities or to deal with abnormal conditions arising in the instance. Each background process is meant for a specific purpose and its role is well-defined.
Background processes consolidate functions that would otherwise be handled by multiple database programs running for each user process. Background processes asynchronously perform I/O and monitor other Oracle database processes to provide increased parallelism for better performance and reliability. A background process is defined as any process that is listed in V$PROCESS and has a non-null value in the pname column. Not all background processes are mandatory for instance. Some are mandatory and some are optional. Mandatory background processes are DBWn, LGWR, CKPT, SMON, PMON, and RECO. All other processes are optional and will be invoked if that particular feature is activated.
Oracle background processes are visible as separate operating system processes in Unix/Linux. In Windows, these run as separate threads within the same service. Any issues related to background processes should be monitored and analyzed from the trace files generated and the alert log.
Background processes are started automatically when the instance is started.
To find out background processes from the database:
SQL> select SID,PROGRAM from v$session where TYPE='BACKGROUND';
To find out background processes from OS:
$ ps -ef|grep ora_|grep SID
Mandatory Background Processes in Oracle
If any one of these 6 mandatory background processes is killed/not running, the instance will be aborted.
1) Database Writer (maximum 20) DBW0-DBW9,DBWa-DBWj
Whenever a log switch occurs as the redo log file is becoming CURRENT to the ACTIVE stage, oracle calls DBWn and synchronizes all the dirty blocks in the database buffer cache to the respective datafiles, scattered or randomly.
The database writer process, known as DBWR in older versions of Oracle, writes new or changed data blocks (known as dirty blocks) in the buffer cache to the data files. Using an LRU algorithm, DBWn writes the oldest, least active blocks first. As a result, the most commonly requested blocks, even if they are dirty blocks, are in memory. Up to 20 DBWn processes can be started, DBW0 through DBW9 and DBWa through DBWj. The number of DBWn processes is controlled by the DB_WRITER_PROCESSES parameter.
Database writer (or Dirty Buffer Writer) process does multi-block writing to disk asynchronously. One DBWn process is adequate for most systems. Multiple database writers can be configured by initialization parameter DB_WRITER_PROCESSES, depends on the number of CPUs allocated to the instance. To have more than one DBWn only make sense if each DBWn has been allocated its own list of blocks to write to disk. This is done through the initialization parameter DB_BLOCK_LRU_LATCHES. If this parameter is not set correctly, multiple DB writers can contend for the same block list.
The possible multiple DBWR processes in RAC must be coordinated through the locking and global cache processes to ensure efficient processing is accomplished.
DBWn will be invoked in the following scenarios:
When the dirty blocks in SGA reach a threshold value, oracle calls DBWn.
When the database is shutting down (normal, transactional, immediate) with some dirty blocks in the SGA, then Oracle calls DBWn.
DBWn has a time-out value (3 seconds by default) and it wakes up whether there are any dirty blocks or not.
When a checkpoint is issued.
When a server process cannot find a clean reusable buffer after scanning a threshold number of buffers.
When a huge table wants to enter into SGA and oracle could not find enough free space where it decides to flush out LRU blocks and which happens to be dirty blocks. Before flushing out the dirty blocks, oracle calls DBWn.
Oracle RAC ping request is made.
When Table DROPED or TRUNCATED.
When tablespace is going to OFFLINE/READ ONLY/BEGIN BACKUP.
2) Log Writer (maximum 1) LGWR
LGWR writes redo data from redo log buffers to (online) redo log files, sequentially.
The Redolog file contains changes to any data file. The content of the redo log file is file ID, block ID, and new content.
LGWR will be invoked more often than DBWn as log files are really small compared to datafiles (KB vs GB). For every small update, we don’t want to open huge gigabytes of datafiles, instead write to the log file.
LGWR, or the log writer process, is in charge of redo log buffer management. LGWR is one of the most active processes in an instance with heavy DML activity. A transaction is not considered complete until LGWR successfully writes the redo information, including the commit record, to the redo log files. In addition, the dirty buffers in the buffer cache cannot be written to the datafiles by DBWn until LGWR has written the redo information.If the redo log files are grouped, and one of the multiplexed redo log files in a group is damaged, LGWR writes to the remaining members of the group and records an error in the alert log file. If all members of a group are unusable, the LGWR process fails and the entire instance hangs until the problem can be corrected.
Redolog file has three stages CURRENT, ACTIVE, INACTIVE and this is a cyclic process. The newly created redo log file will be in a UNUSED state.
When the LGWR is writing to a particular redo log file, that file is said to be in CURRENT status. If the file is filled up completely then a log switch takes place and the LGWR starts writing to the second file (this is the reason every database requires a minimum of 2 redo log groups). The file which is filled up now becomes from CURRENT to ACTIVE.
The log writer will write synchronously to the redo log groups in a circular fashion. If any damage is identified with a redo log file, the log writer will log an error in the LGWR trace file and the alert log. Sometimes, when additional redo log buffer space is required, the LGWR will even write uncommitted redo log entries to release the held buffers. LGWR can also use group commits (multiple committed transactions' redo entries taken together) to write to redo logs when a database is undergoing heavy write operations.
In RAC, each RAC instance has its own LGWR process that maintains that instance’s thread of redo logs.
LGWR will be invoked in the following scenarios:
LGWR is invoked whenever 1/3rd of the redo buffer is filled up.
Whenever the log writer times out (3sec)
Whenever 1MB of redo log buffer is filled (This means that there is no sense in making the redo log buffer more than 3MB).
Shutting down the database.
Whenever a checkpoint event occurs.
When a transaction is completed (either committed or rollbacked) oracle calls the LGWR and synchronizes the log buffers to the redo log files and then only passes on the acknowledgment back to the user. This means the transaction is only guaranteed if we say commit unless we receive the acknowledgment. When a transaction is committed, a System Change Number (SCN) is generated and tagged to it. The log writer puts a commit record in the redo log buffer and writes it to disk immediately along with the transaction's redo entries. Changes to actual data blocks are deferred until a convenient time (Fast-Commit mechanism).
When DBWn signals the writing of redo records to disk. All redo records associated with changes in the block buffers must be written to disk first (The write-ahead protocol). While writing dirty buffers, if the DBWn process finds that some redo information has not been written, it signals the LGWR to write the information and waits until the control is returned.
3) Checkpoint (maximum 1) CKPT
Checkpoint is a background process that triggers the checkpoint event, to synchronize all database files with the checkpoint information. It ensures data consistency and faster database recovery in case of a crash.
The checkpoint process, or CKPT, helps to reduce the amount of time required for instance recovery. During a checkpoint, CKPT updates the header of the control file and the datafiles to reflect the last successful System Change Number (SCN). A checkpoint occurs automatically every time a redo log file switch occurs. The DBWn processes routinely write dirty buffers to advance the checkpoint from where instance recovery can begin, thus reducing the Mean Time to Recovery (MTTR).
When a checkpoint occurs it will invoke the DBWn and update the SCN block of all datafiles and the control file with the current SCN. This is done by LGWR. This SCN is called checkpoint SCN.
Checkpoint event can occur in the following conditions:
Whenever the database buffer cache fills up.
Whenever times out (3 seconds until 9i, 1 second from 10g).
Log switch occurred
Whenever the manual log switch is done.
SQL> ALTER SYSTEM SWITCH LOGFILE;
Manual checkpoint.
SQL> ALTER SYSTEM CHECKPOINT;
Graceful shutdown of the database.
Whenever the BEGIN BACKUP command is issued.
When the time specified by the initialization parameter LOG_CHECKPOINT_TIMEOUT (in seconds), exists between the incremental checkpoint and the tail of the log.
When the number of OS blocks specified by the initialization parameter LOG_CHECKPOINT_INTERVAL, exists between the incremental checkpoint and the tail of the log.
The number of buffers specified by the initialization parameter FAST_START_IO_TARGET required to perform roll-forward is reached.
Oracle 9i onwards, the time specified by the initialization parameter FAST_START_MTTR_TARGET (in seconds) is reached and specifies the time required for crash recovery. The parameter FAST_START_MTTR_TARGET replaces LOG_CHECKPOINT_INTERVAL and FAST_START_IO_TARGET, but these parameters can still be used.
4) System Monitor (maximum 1) SMON
If the database is crashes (power failure) and the next time we restart the database SMON observes that last time the database was not shut down gracefully. Hence it requires some recovery, which is known as INSTANCE CRASH RECOVERY. When performing the crash recovery before the database is completely open, if it finds any transaction committed but not found in the datafiles, will now be applied from redo log files to data files.
SMON is the System Monitor process. In the case of a system crash or instance failure, due to a power outage or CPU failure, the SMON process performs crash recovery by applying the entries in the online redo log files to the data files. In addition, temporary segments in all tablespaces are purged during system restart. One of SMON’s routine tasks is to coalesce the free space in tablespaces regularly if the tablespace is dictionary managed.
If SMON observes some uncommitted transaction that has already updated the table in the data file, is going to be treated as an in-doubt transaction and will be rolled back with the help of the before image available in rollback segments.
SMON also cleans up temporary segments that are no longer in use.
It also coalesces contiguous free extents in dictionary-managed tablespaces that have PCTINCREASE set to a non-zero value.
In the RAC environment, the SMON process of one instance can perform instance recovery for other instances that have failed.
SMON wakes up about every 5 minutes to perform housekeeping activities.
5) Process Monitor (maximum 1) PMON
If a client has an open transaction that is no longer active (client session is closed) then PMON comes into the picture and that transaction becomes in doubt transaction that will be rolled back.
PMON is responsible for performing recovery if a user process fails. It will roll back uncommitted transactions. If the old session is locked any resources that will be unlocked by PMON.
PMON is responsible for cleaning up the database buffer cache and freeing resources that were allocated to a process.
PMON also registers information about the instance and dispatcher processes with the Oracle (network) listener. PMON also checks the dispatcher & server processes and restarts them if they have failed. Since Oracle 12c, the LREG (Listener REGistration) process has been taking care of listener operations.
PMON wakes up every 3 seconds to perform housekeeping activities.
In RAC, PMON’s role as a service registration agent is particularly important.
If a user connection is dropped, or a user process otherwise fails, PMON, also known as the Process Monitor, does the cleanup work. It cleans up the database buffer cache along with any other resources that the user connection was using. For example, a user session may be updating some rows in a table, placing a lock on one or more of the rows. A thunderstorm knocks out the power at the user’s desk, and the SQL*Plus session disappears when the workstation is powered off. Within moments, PMON will detect that the connection no longer exists and perform the following tasks:
■ Roll back the transaction that was in progress when the power went out.
■ Mark the transaction’s blocks as available in the buffer cache.
■ Remove the locks on the affected rows in the table.
■ Remove the process ID of the disconnected process from the list of active processes.
PMON will also interact with the listeners by providing information about the status of the
instance for incoming connection requests.
6) Recoverer (maximum 1) RECO [Mandatory from Oracle 10g]
This process is intended for recovery in distributed databases. The distributed transaction recovery process finds pending distributed transactions and resolves them. All in-doubt transactions are recovered by this process in the distributed database setup. RECO will connect to the remote database to resolve pending transactions.
Pending distributed transactions are two-phase commit transactions involving multiple databases. The database that the transaction started is normally the coordinator. It will send requests to other databases involved in a two-phase commit if they are ready to commit. If a negative request is received from one of the other sites, the entire transaction will be rolled back. Otherwise, the distributed transaction will be committed on all sites. However, there is a chance that an error (network-related or otherwise) causes the two-phase commit transaction to be left in a pending state (i.e. not committed or rolled back). It's the role of the RECO process to liaise with the coordinator to resolve the pending two-phase commit transaction. RECO will either commit or roll back this transaction.
The RECO, or recoverer process, handles failures of distributed transactions (that is, transactions that include changes to tables in more than one database). If a table in the CCTR database is changed along with a table in the WHSE database, and the network connection between the databases fails before the table in the WHSE database can be updated, RECO will roll back the failed transaction.

Optional Background Processes in Oracle
Archiver (maximum 10) ARC0-ARC9
The ARCn process is responsible for writing the online redo log files to the mentioned archive log destination after a log switch has occurred. ARCn is present only if the database is running in archive log mode and automatic archiving is enabled. The log writer process is responsible for starting multiple ARCn processes when the workload increases. Unless ARCn completes the copying of a redo log file, it is not released to the log writer for overwriting.
If the database is in ARCHIVELOG mode, then the archiver process, or ARCn, copies redo logs to one or more destination directories, devices, or network locations whenever a redo log fills up and redo information starts to fill the next redo log in sequence. Optimally, the archiver process finishes before the filled redo log is needed again; otherwise, serious performance problems occur—users cannot complete their transactions until the entries are written to the redo log files, and the redo log file is not ready to accept new entries because it is still being written to the archive location. There are at least three potential solutions to this problem: make the redo log files larger, increase the number of redo log groups, and increase the number of ARCn processes. Up to 30 ARCn processes can be started for each instance by increasing the value of the LOG_ARCHIVE_MAX_PROCESSES initialization parameter.
The number of archiver processes that can be invoked initially is specified by the initialization parameter LOG_ARCHIVE_MAX_PROCESSES (by default 2, max 10). The actual number of archiver processes in use may vary based on the workload.
ARCH processes, running on the primary database, select archived redo logs and send them to the standby database. Archive log files are used for media recovery (in case of a hard disk failure and for maintaining an Oracle standby database via log shipping). Archives the standby redo logs applied by the managed recovery process (MRP).
In RAC, the various ARCH processes can be utilized to ensure that copies of the archived redo logs for each instance are available to the other instances in the RAC setup should they be needed for recovery.
Coordinated Job Queue Processes (maximum 1000) CJQ0/Jnnn
Job queue processes carry out batch processing. All scheduled jobs are executed by these processes. The initialization parameter JOB_QUEUE_PROCESSES specifies the maximum job processes that can be run concurrently. These processes will be useful in refreshing materialized views.
This is Oracle’s dynamic job queue coordinator. It periodically selects jobs (from JOB$) that need to be run, scheduled by the Oracle job queue. The coordinator process dynamically spawns job queue slave processes (J000-J999) to run the jobs. These jobs could be PL/SQL statements or procedures on an Oracle instance.
CQJ0 - The job queue controller process wakes up periodically and checks the job log. If a job is due, it spawns Jnnnn processes to handle jobs.
From Oracle 11g release2, DBMS_JOB, and DBMS_SCHEDULER work without setting JOB_QUEUE_PROCESSES. Before 11gR2, the default value is 0, and from 11gR2 the default value is 1000.
Dedicated Serve
Dedicated server processes are used when MTS is not used. Each user process gets a dedicated connection to the database. These user processes also handle disk reads from database datafiles into the database block buffers.
LISTENER
The LISTENER process listens for connection requests on a specified port and passes these requests to either a distributor process if MTS is configured, or to a dedicated process if MTS is not used. The LISTENER process is responsible for load balance and failover in case a RAC instance fails or is overloaded.
CALLOUT Listener
Used by internal processes to make calls to externally stored procedures.
Lock Monitor (maximum 1) LMON
The lock monitor manages global locks and resources. It handles the redistribution of instance locks whenever instances are started or shut down. The lock monitor also recovers instance lock information before the instance recovery process. The lock monitor coordinates with the Process Monitor (PMON) to recover dead processes that hold instance locks.
Lock Manager Daemon (maximum 10) LMDn
LMDn processes manage instance locks that are used to share resources between instances. LMDn processes also handle deadlock detection and remote lock requests.
Global Cache Service (LMS)
In an Oracle Real Application Clusters environment, this process manages resources and provides inter-instance resource control.
Lock processes (maximum 10) LCK0- LCK9
The instance locks that are used to share resources between instances are held by the lock processes.
Block Server Process (maximum 10) BSP0-BSP9
Block server Processes have to do with providing a consistent read image of a buffer that is requested by a process of another instance, in certain circumstances.
Queue Monitor (maximum 10) QMN0-QMN9
This is the advanced queuing time manager process. QMNn monitors the message queues. QMN is used to manage Oracle Streams Advanced Queuing.
Event Monitor (maximum 1) EMN0/EMON
This process is also related to advanced queuing and is meant to allow a publish/subscribe style of messaging between applications.
Dispatcher (maximum 1000) Dnnn
Intended for multi-threaded server (MTS) setups. Dispatcher processes listen to and receive requests from connected sessions and place them in the request queue for further processing. Dispatcher processes also pick up outgoing responses from the result queue and transmit them back to the clients. Dnnn are mediators between the client processes and the shared server processes. The maximum number of dispatcher processes can be specified using the initialization parameter MAX_DISPATCHERS.
Shared Server Processes (maximum 1000) Snnn
Intended for multi-threaded server (MTS) setups. These processes pick up requests from the call request queue, process them, and then return the results to a result queue. These user processes also handle disk reads from database datafiles into the database block buffers. The number of shared server processes to be created at instance startup can be specified using the initialization parameter SHARED_SERVERS. Maximum shared server processes can be specified by MAX_SHARED_SERVERS.
Parallel Execution/Query Slaves (maximum 1000) Pnnn
These processes are used for parallel processing. It can be used for parallel execution of SQL statements or recovery. The maximum number of parallel processes that can be invoked is specified by the initialization parameter PARALLEL_MAX_SERVERS.
Trace Writer (maximum 1) TRWR
The trace writer writes trace files from an Oracle internal tracing facility.
Input/Output Slaves (maximum 1000) Innn
These processes are used to simulate asynchronous I/O on platforms that do not support it. The initialization parameter DBWR_IO_SLAVES is set for this purpose.
Data Guard Monitor (maximum 1) DMON
The Data Guard broker process. DMON is started when Data Guard is started. This broker controller process is the main broker process and is responsible for coordinating all broker actions as well as maintaining the broker configuration files. This process is enabled/disabled with the DG_BROKER_START parameter.
Data Guard Broker Resource Manager RSM0
The RSM process is responsible for handling any SQL commands used by the broker that need to be executed on one of the databases in the configuration.
Data Guard NetServer/NetSlave NSVn
These are responsible for making contact with the remote database and sending any work items to the remote database. From 1 to n these network server processes can exist. NSVn is created when a Data Guard broker configuration is enabled. There can be as many NSVn processes (where n is 0- 9 and A-U) created as there are databases in the Data Guard broker configuration.
DRCn
These network receiver processes establish the connection from the source database NSVn process. When the broker needs to send something (e.g. data or SQL) between databases, it uses this NSV to DRC connection. These connections are started as needed.
Data Guard Broker Instance Slave Process INSV
Performs Data Guard broker communication among instances in an Oracle RAC environment
Data Guard Broker Fast Start Failover Pinger Process FSFP
Maintains a fast-start failover state between the primary and target standby databases. FSFP is created when fast-start failover is enabled.
LGWR Network Server process LNS
In Data Guard, the LNS process performs actual network I/O and waits for each network I/O to complete. Each LNS has a user-configurable buffer that is used to accept outbound redo data from the LGWR process. The NET_TIMEOUT attribute is used only when the LGWR process transmits redo data using an LGWR Network Server(LNS) process.
Managed Recovery Process MRP
In the Data Guard environment, this managed recovery process will apply archived redo logs to the standby database.
Remote File Server process RFS
The remote file server process, in the Data Guard environment, on the standby database receives archived redo logs from the primary database.
Logical Standby Process LSP
The logical standby process is the coordinator process for a set of processes that concurrently read, prepare, build, analyze, and apply completed SQL transactions from the archived redo logs. The LSP also maintains metadata in the database. The RFS process communicates with the logical standby process (LSP) to coordinate and record which files arrived.
Wakeup Monitor Process (maximum 1) WMON
This process was available in older versions of Oracle to alarm other processes that are suspended while waiting for an event to occur. This process is obsolete and has been removed.
Recovery Writer (maximum 1) RVWR
This is responsible for writing flashback logs (to FRA).
Fetch Archive Log (FAL) Server
Services requests for archive redo logs from FAL clients running on multiple standby databases. Multiple FAL servers can be run on a primary database, one for each FAL request.
Fetch Archive Log (FAL) Client
Pulls archived redo log files from the primary site. Initiates the transfer of archived redo logs when it detects a gap sequence.
Data Pump Master Process DMnn
Creates and deletes the master table at the time of export and import. The master table contains the job state and object information. Coordinates the Data Pump job tasks performed by Data Pump worker processes and handles client interactions. The Data Pump master (control) process is started during job creation and coordinates all tasks performed by the Data Pump job. It handles all client interactions and communication, establishes all job contexts, and coordinates all worker process activities on behalf of the job. Creates the Worker Process.
Data Pump Worker Process DWnn
It performs the actual heavy-duty work of loading and unloading data. It maintains the information in the master table. The Data Pump worker process is responsible for performing tasks that are assigned by the Data Pump master process, such as the loading and unloading of metadata and data.
Shadow Process
When the client logs in to an Oracle Server the database creates an Oracle process to service Data Pump API.
Client Process
The client process calls the Data Pump API.
New Background Processes in Oracle 10g
Memory Manager (maximum 1) MMAN
MMAN dynamically adjusts the sizes of the SGA components like buffer cache, large pool, shared pool, and java pool and serves as an SGA memory broker. It is a new process added to Oracle 10g as part of automatic shared memory management.
Memory Monitor (maximum 1) MMON
MMON monitors SGA and performs various manageability-related background tasks. MMON, the Oracle 10g background process, is used to collect statistics for the Automatic Workload Repository (AWR).Tracks/aggregates space utilization while performing regular space management activities.
Memory Monitor Light (maximum 1) MMNL
New background process in Oracle 10g. This process performs frequent and lightweight manageability-related tasks, such as session history capture and metrics computation. This process will flush the ASH buffer to AWR tables when the buffer is full or a snapshot is taken.
Change Tracking Writer (maximum 1) CTWR
CTWR will be useful in RMAN. Optimized incremental backups using block change tracking (faster incremental backups) using a file (named block change tracking file). CTWR (Change Tracking Writer) is the background process responsible for tracking the blocks.
ASMB
This ASMB process is used to provide information to and from cluster synchronization services used by ASM to manage the disk resources. It's also used to update statistics and provide a heartbeat mechanism.
Re-Balance RBAL
RBAL is the ASM-related process that performs rebalancing of disk resources controlled by ASM.
Actual Rebalance ARBx
ARBx is configured by ASM_POWER_LIMIT.
Autotask Background Process (ABP)
It translates tasks into jobs for execution by the scheduler. It determines the list of jobs that must be created for each maintenance window. Stores task execution history in the SYSAUX tablespace. It is spawned by the MMON background process at the start of the maintenance window.
File Monitor (FMON)
The database communicates with the mapping libraries provided by storage vendors through an external non-Oracle Database process that is spawned by a background process called FMON. FMON is responsible for managing the mapping information. When you specify the FILE_MAPPING initialization parameter for mapping data files to physical devices on a storage subsystem, then the FMON process is spawned.
Dynamic Intimate Shared Memory (DISM)
By default, Oracle uses intimate shared memory (ISM) instead of standard System V shared memory on the Solaris Operating system. When a shared memory segment is made into an ISM segment, it is mapped using large pages and the memory for the segment is locked (i.e., it cannot be paged out). This greatly reduces the overhead due to process context switches, which improves Oracle's performance linearity under load.
New Background Processes in Oracle 11g
ACMS - Atomic controlfile to Memory Server
DBRM - Database Resource Manager
DIA0 - Diagnosibility process 0
DIAG - Diagnosibility process
FBDA - Flashback Data Archiver,
Background process fbda captures data asynchronously,
Every 5 minutes (default), more frequent intervals based on activity.
GTX0 - Global Transaction Process 0
KATE - Konductor (Conductor) of ASM Temporary Errands
MARK - Mark Allocation unit for Resync Koordinator (coordinator)
SMCO - Space Manager
VKTM - Virtual Keeper of TiMe process
W000 - Space Management Worker Processes
ABP - Autotask Background Process
New background processes in Oracle Database 12c
LREG (Listener Registration)
SA (SGA Allocator)
RM









Awesome doc...
ReplyDelete